Predicting the next Top 100
![]()
Popularity is one key factor for an artist to release music. One way of measuring popularity is the position of a song in charts. Billboard updates their chart every week, adding or removing songs according to the times it has been played on radio and streaming platforms. If a song is popular in Billboard, that means, if that song can get to be featured in one of the many charts on Billboard, it is likely to ensure a good financial return to the artist and, by extent, to their label. Spotify is the most popular streaming platform and provides an API through which one can access features of any song. In this exercise, I try to find a methodology to predict a song’s popularity based on the Billboard Hot 100 charts for the past 20 years, and features for those songs available through Spotify API.
A Google Colab notebook for this skill is here.
Introduction
With an always growing market and being affected by the current situation in the world, music streaming services are one of the preferred ways of consuming music. It is estimated that in the world exist around 400 million subscribers. Spotify and Apple Music account for 50% of them. As with any market, it is always important to understand what gives value to a product, in this case, albums and songs, and how can artists profit that information to know when to release an album among other strategies. All the streaming services provide information about what songs and albums are the most popular among their subscribers. However, if one relies only on that information, there could be certain limitations as the number of users, availability of the service in certain regions, etc. By using a global third party popularity system, this approach aims to better understand the popularity of a song independently of any service. In this work, I consider a song to be popular if it reaches any position in the Billboard Hot 100 chart.
Although I aim to be as platform-independent as I can be, I will use Spotify API to extract features and use that data to train a machine learning algorithm to predict whether there is a possibility for a song to be featured in Billboard’s Hot 100 chart any week. Deezer also has an API with the potential to be a source of information for this work, a way to improve the independence of any platform could be cross-validating the data in two or more platforms.
Methodology
Predicting the popularity of a song can be treated as a classification problem. With this approach I try to address the question of how likely it is for a song to be popular, as understood as being featured in Billboard’s Hot 100. The traditional approach to a classification problem is get the data, train the model, test the model, and deploy the model. In our case, deployment of the model will be making predictions for existing songs of whether they have the potential to be popular or not.
Data acquisition could be treated as a different problem; combining two different APIs can be complicated. Billboard does not have an API active, however it is likely that it did have an API in the past. Several solutions exist providing packages and language bindings for Billboard API that work at this moment.
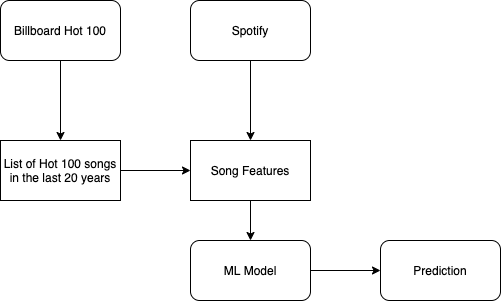
Image 1: Simplified System Diagram
The approach I try to follow is:
- Get song and artist from Billboard Hot 100 for the past 20 years
- Get features from Spotify API using song and artist
- Train the model using the acquired dataset
- Test the model with testing dataset
- Test the model with data not in any of the previous datasets
Getting data from Billboard
Data acquisition from Billboard was straightforward. I used billboard-charts to get current and past data. This package provides information for each song in the form a ChartData Object. This object has many attributes among which are song name and artist. It also provides the peak position, number of weeks this song has been in the chart, and if the song is new or not.
hot-100 chart from 2020-09-05
-----------------------------
1. 'Dynamite' by BTS
2. 'WAP' by Cardi B Featuring Megan Thee Stallion
3. 'Laugh Now Cry Later' by Drake Featuring Lil Durk
4. 'Rockstar' by DaBaby Featuring Roddy Ricch
5. 'Blinding Lights' by The Weeknd
6. 'Whats Poppin' by Jack Harlow Featuring DaBaby, Tory Lanez & Lil Wayne
7. 'Watermelon Sugar' by Harry Styles
8. 'Roses' by SAINt JHN
9. 'Savage Love (Laxed - Siren Beat)' by Jawsh 685 x Jason Derulo
10. 'Before You Go' by Lewis Capaldi
Features from Spotify
Spotify allow a developer to access their API and get data for songs, albums, artists, etc. For this work I am using the get Audio Features method. The data that Spotify provides in this method is:
- Duration: The duration of the track in milliseconds.
- Key: The estimated overall key of the track.
- Mode: Mode indicates the modality (major or minor) of a track.
- Time Signature: An estimated overall time signature of a track. The time signature (meter) is a notational convention to specify how many beats are in each bar (or measure).
- Acousticness: A confidence measure from 0.0 to 1.0 of whether the track is acoustic.
- Danceability: Danceability describes how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity
- Energy: Energy is a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity.
- Instrumentalness: Predicts whether a track contains no vocals.
- Liveness: Detects the presence of an audience in the recording.
- Loudness: The overall loudness of a track in decibels (dB).
- Speechiness: Speechiness detects the presence of spoken words in a track.
- Valence: A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track.
- Tempo: The overall estimated tempo of a track in beats per minute (BPM).
Spotify Features example:
{'danceability': 0.934,
'energy': 0.443,
'key': 1,
'loudness': -7.541,
'mode': 1,
'speechiness': 0.41,
'acousticness': 0.0272,
'instrumentalness': 0,
'liveness': 0.0889,
'valence': 0.359,
'tempo': 133.026,
'type': 'audio_features',
'id': '051wt8AyLFgYnVuberd3vO',
'uri': 'spotify:track:051wt8AyLFgYnVuberd3vO',
'track_href': 'https://api.spotify.com/v1/tracks/051wt8AyLFgYnVuberd3vO',
'analysis_url': 'https://api.spotify.com/v1/audio-analysis/051wt8AyLFgYnVuberd3vO',
'duration_ms': 187541,
'time_signature': 4}
Issues with getting data:
After getting the latest chart, we now would have to get data from Spotify API. The main limitation we have is that there is not a direct link between the Billboard data and the Spotify API. To get one unique ID we can get audio features with, we would need to perform a search using either the title, the artist, or both, to get such Id. However, there are some challenges that we would need to address before actually getting data from Spotify.
- Titles are not consistent in Billboard and Spotify: In some cases, specially when a song is performed by more than one artist, the title changes. For example: ‘WAP’ by Cardi B Featuring Megan Thee Stallion can be found as ‘WAP Ft. Megan Thee Stalion’ or ‘WAP’. This inconsistence makes it hard to find a particular song without having to intervene.
- Songs can have a common name: This means that a song can have more than one search result with the same name but different artist, making it a different song. Using the artist in the search helps to get the correct song. However, in some cases, and specially with songs that have more than one artist, using all of them in the search is counterefective; in more than one case the results were empty even if the song exists in Spotify.
- A song can have different names: Taking one song, specially those with bad words in the title, can be subjects of censorship to comply with terms of service with some streaming services. This presents a different challenge also because, in some cases, the way artists change the names is with ‘*’. That character is also a wildcard when doing a search. It can impact the results we get from searching a song with those characters.
- Artists behave strangely in Spotify API: When doing a search for a song, even using artist in the search term, the results are in a format that is not easy to work with. It appeared to be a JSON object with several different objects in it. One analogy that can work to understand how the results were too complex is: an array of arrays, one for each result, with an array of artists in it. The information in the array could go up to four or five levels of arrays within arrays.
- The number of results could go to thousands: If the song has different verions (remix, explicit, etc), the search results would throw all of them, even when using the artist to filter. Because the Spotify API also uses algorithms to understand what the User would want to search and suggest other options, the results could go too big to handle. Because of all these complications, a very strong option to get a single ID to search audio features with was manually looking for all the songs, but I was still convinced that a Spotify search and a clean up of the data was the most strong and solid option to get the data.
How much data is too much data?
The original idea of this work was to get up to 20 years of Billboard Charts data and then feed an algorithm with it. In 20 years there are 1040 weeks, and each week a new Billboard chart is published, meaning that, in total, I would have 104,000 data entries in the database to train the algorithm. As stated before, the most strong option to get the Id to be used later to get audio features was a automated option.
The search query was something like this:
"Song name" + "First word of the artist name"
For example, ‘WAP’ by Cardi B Featuring Megan Thee Stallion would be searched as:
WAP Cardi
‘Dynamyte’ by BTS would be searched as:
Dynamyte BTS
This was use in some cases but, in others, the number of results was too big. After trying to get the Ids using an algorithm, and crashing my computer because of the size that the dabase could get to (Up to 4 GB of only JSON objects in memory), I decided to get the Ids by manually searching the songs in Spotify. However, manually looking for 104,000 data entries was simply something that I was not going to do.
Songs tend to be more than one week in the Billboard Chart (There are songs that only appear one time in the chart and then never appear again), so I decided to look for the unique values in the entire database and then manually search for their Ids. The total number of unique records was around 8K. Still big, but achievable.
And then time came
As you may think, manually searching for the Ids using Spotify web is a very time consuming task and by the 800th record I had already spend more than the time I would have liked to spend. So decided to, just for the sake of this experiment, use the first 1000 records of the database. I acknowledge that it is not representative and that it might be biased, for future developments in this area, I would recomend to work with more people to address this issue by either, developing a very strong algorithm to get the data from Spotify API or by spending more time manually searching for the Id. This last option would be the most effective way of getting accurate Ids for the songs, but it is also very time consuming.
Getting features for each song
Now having a unique Id (Url of the song), we could look for the features of that song. Using Spotipy audio_features
Looping through all the URLs, we got the features for the first 1000 songs of the charts and created a dataset here.
To balance the dataset, and provide some records of songs not in the Billboard charts, I looked for 1,000 songs using random search strings, consisting mainly of characters alone, and created a second dataset labeled as “Not in the chart”. We also got features for these songs using a similar approach as the cells above. The second dataset (non-hits) is here.
Preparing the datasets
I go in more detail in the Google Colab Notebook linked at the top of this page.
In order to keep numbers balanced, that is, 50% of the dataset should be from hits and 50% from non-hits, we create the train and test datasets first and then combine them to still have he 50-50 ratio.
Binary Classification
The question “Can we predith, based on the feature of previous songs, if a song can make it to the Billboard Hot-100” can be formulated as a binary classification problem. A song either makes it to the chart or it doesn’t.
For this exercise, I will try different classifiers from Scikit Learn trying to get one model that can accurately predict whether the song will be famous or not.
Summary of findings
After using different binary classificators from Scikit Learn, this is the summary of the performanc of each one
| Model | Accuracy |
|---|---|
| K Neighbors Algorithm | 54.5% |
| Linear SVC (Support Vector Classifier) | 53.5% |
| RBF (Radial Basis Function) S | C 54% |
| Gaussian Process | 49.1% |
| Decision Tree Classifier | 56.1% |
| Random Forest Classifier | 60.3% |
| Neural Network | 56.6% |
| Adaboost Classifier | 59.3% |
| Naive Bayes | 56.1% |
| QDA (Quadratic Discriminant Analysis) | 56.5% |
Using pyTorch
I also used a Neural Network with pyTorch trying to answer the research question.
| Model | Accuracy |
|---|---|
| pyTorch Neural Network | 50.4% |
Findings
Despite trying different classifiers with Machine Learning and Deep Learning, we cannot offer a conclusive answer to the question “Can we predict whether a new song will be a hit or not?”. The most promising model was Random Forest classifier with 60% of accuracy. However, because of the nature of a binary classifcator, we cannot say that it is a good model.
There are two main factors that could have impacted the results:
- Small datasets compared to the number of available data.
- Entirely random no-hit data.
- A third factor that might have an impact is those songs that only appeared one week in the chart. Since they are technically in the chart, they are taken into account but, doing a qualitative analysis of the song, might reveal that such song only peaked because an artist released an album in that song. In other words, the model could potentially include only songs that were more than one week in the chart.
In conclusion:
This exercise did not offer a conclusive answer to the research question.
Ways to improve and next steps
I can think of two main ways to improve this exercise:
- Spend more time to gather data of, at least, the 8k unique values of songs in the 104k entries dataset Review what songs are actually in the no-hits dataset.
- Also, even with those improvements, the model would fail to address external factors to the songs, such as the weight that an artist have in their own songs (i.e, If an artist was previously in the chart, they would be more likely to release another hit song). One of the ways to address this, and could be to include another feature based on the number of songs that an artist have previously had in the chart, or the number of weeks that an artist have had a song in the chart.